Architecture Overview¶
While a basic implementation of an RL algorithm can fit in a single file, a high-throughput RL system requires a rather sophisticated architecture. This document describes the high-level design of Sample Factory.
The following diagram shows the main components of the system and the data flow between them. Please see sections below for more details.
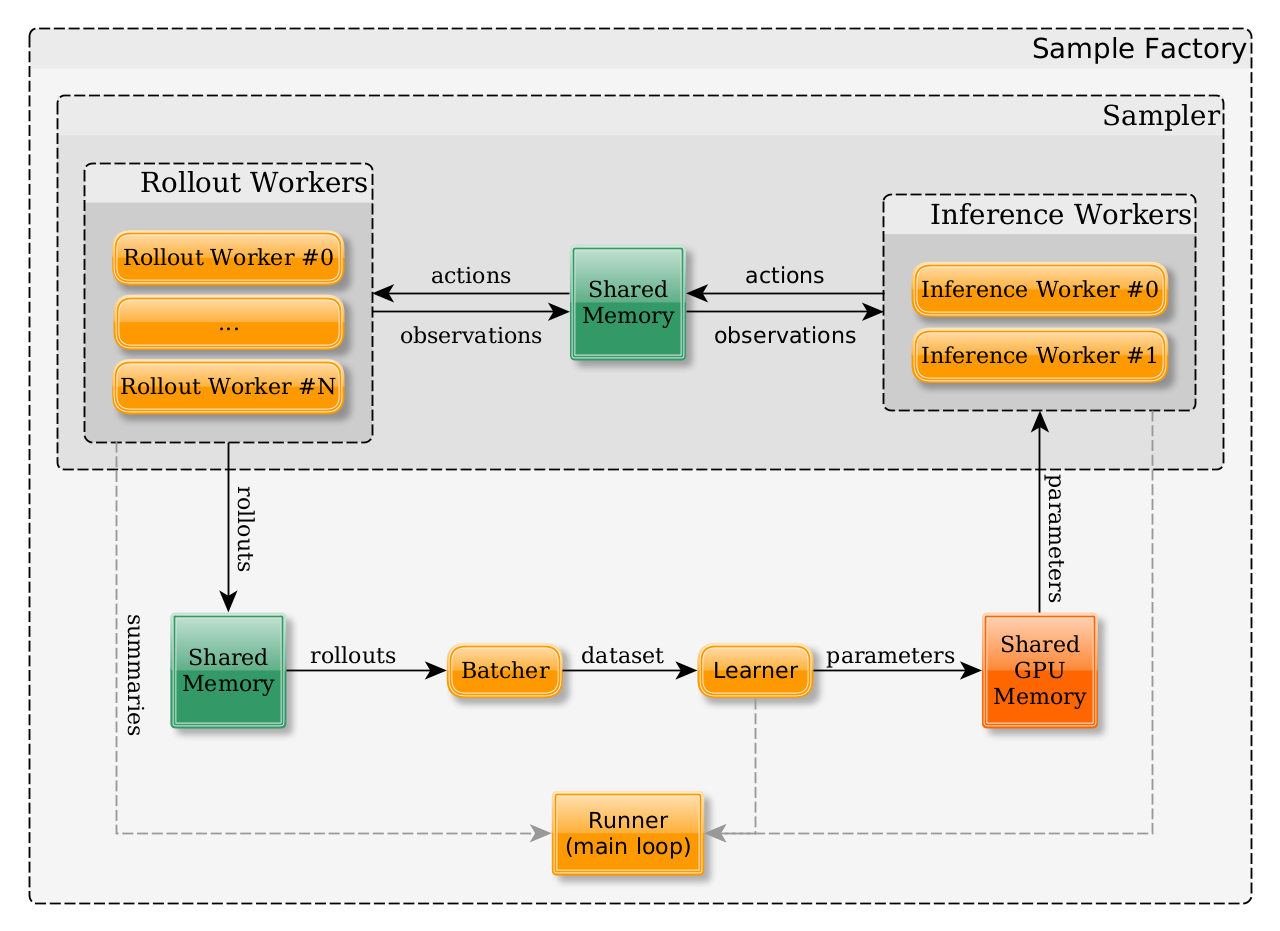
High-level design¶
At the core of Sample Factory structure is the idea that RL training can be split into multiple largely independent components, each one of them focusing on a specific task. This enables a modular design where these components can be accelerated/parallelized independently, allowing us to achieve the maximum performance on any RL task.
Components interact asynchronously by sending and receving messages (aka signals, see a dedicated section on message passing). Typically separate components live on different event loops in different processes, although the system is agnostic of whether this is true and it is thus possible to run multiple (or even all components) on a single event loop in a single process.
Instead of explicitly sending the data between components (i.e. by serializing observations and sending them across processes), we choose to send the data through shared memory buffers. Each time a component needs to send data to another component, it writes the data to a shared memory buffer and sends a signal containing the buffer ID (essentially a pointer to data). This massively reduces the overhead of message passing.
Components¶
Each component is dedicated to a specific task and can be seen as a data processing engine (i.e. each component gets some input by receiving signals, executes a computation, and broadcasts the results by emitting its own signals).
These are the main components of Sample Factory:
- Rollout Workers are responsible for environment simulation. Rollout workers receive actions from the policy,
do environment
step()and produce observations after each step and full trajectories after--rolloutsteps. - Inference Workers receive observations and hidden states and produce actions. The policy on each inference worker is updated after each SGD step on the learner.
- Batcher receives trajectories from rollout workers, puts them together and produces datasets of data for the learner.
- Learner gets batches of data from the batcher, splits them into minibatches and does
--num_epochsof stochastic gradient descent. After each SGD step the updated weights are written to shared memory buffers and the corresponding signal is broadcasted. -
Runner is a component that bootstraps the whole system, receives all sorts of statistics from other components and takes care of logging and summary writing.
-
Sampler, although technically its own component that can send and receive signals, in the typical configuration is nothing more than a thin wrapper around Rollout/Inference workers and serves as an interface to the rest of the system. (Although this interface allows us to create alternative samplers i.e. single-process synchronous JAX-optimized sampler is an idea)
Rollout Workers¶
The number of rollout workers is controlled by --num_workers. Each rollout worker can simulate one or multiple environments
serially in the same process. The number of environments per worker is controlled by --num_envs_per_worker.
Each rollout worker contains >= 1 of VectorEnvRunner objects, the number of which is controlled by --worker_num_splits.
The default value of this parameter is 2, which enables double-buffered sampling. The number of envs on each
VectorEnvRunner is thus num_envs_per_worker // worker_num_splits and therefore --num_envs_per_worker must be divisible by --worker_num_splits.
Inference Workers¶
Each policy (see multi-policy training) has >= 1 corresponding inference workers
which generate actions for the agents controlled by this policy.
The number of inference workers is controlled by --policy_workers_per_policy.
Batcher¶
There's typically a single batcher per policy in the system. The batcher receives trajectories from rollout workers and puts them together into a dataset available for training. In batched sampling mode this is pretty much a no-op, the batcher just passes the data through. In non-batched sampling mode this is a non-trivial process, since rollouts from different workers finish asynchronously and need to be put in the contiguous tensor for minibatch SGD.
Although batcher is it's own component, in the default configuration we run it in the same process as the learner (but in a separate thread) in order to minimize the number of CUDA contexts and thus VRAM usage.
Learner¶
There's typically a single learner per policy in the system. Trajectory datasets flow in and updated parameters flow out.
Terminology¶
Some terminology used in the codebase and in the further documentation:
- rollout or trajectory is a sequence of observations, actions, rewards, etc. produced by a single agent.
- dataset (or training batch or sometimes just batch) is a collection of trajectories produced by >=1 agents.
- Datasets are split into minibatches and >=1 epochs of SGD are performed.
Minibatch size is determined by
--batch_sizeand number of epochs is determined by--num_epochs. Dataset size isbatch_size * num_batches_per_epoch, and in totalbatch_size * num_batches_per_epoch * num_epochsSGD steps are performed on each dataset (sorry for the obvious confusion between "batch" and "minibatch" terms, the parameter names are kept largely for legacy reasons). - signals are messages sent between components. Signals are connected to slots, which are functions that are called when a signal is received. This mechanism is inspired by Qt's signals and slots (see the dedicated section on message passing).
- shared memory buffers are PyTorch tensors shared between processes, created with
share_memory_()method.