Metrics Reference¶
General information¶
Each experiment will have at least the following groups of metrics on Tensorboard/Wandb:
lenperfpolicy_statsrewardstatstrain
Plus new sections (groups) are created for each custom metric with key in <group_name>/<metric_name> format (see Custom Metrics section).
Summaries such as len, perf, reward are averaged over the last 100 data points to filter noise
(this can be changed by --stats_avg=N argument). These summaries are written to Tensorboard/Wandb every
--experiment_summaries_interval seconds (10 seconds by default).
train summaries are not averaged and just represent the values from the latest minibatch on the learner.
The reporting rate for train summaries is decayed over time to reduce the size of the log files.
The schedule is controlled by summary_rate_decay_seconds variable in learner.py.
len¶
len/len, len/len_max, len/len_min are simply episode lengths measured after frameskip.
If your environment uses frameskip=4 and the reported episode length is 400, it means that 400 environment steps
were simulated but the agent actually observed only 100 frames.
perf¶
perf/_fps and perf/_sample_throughput represent throughput as measured in different parts of the algorithm.
perf/_sample_throughput is the number of observations processed (or actions generated) by the inference worker, i.e. pure
sampling throughput measured before frameskipping is taken into account.
perf/_fps is the number of observations/actions processed by the learner and measured after frameskipping.
For example with frameskip=4, perf/_sample_throughput will be 4 times smaller than perf/_fps. If this is not the case,
it means that the learner had to throw away some trajectories which can happen for multiple reasons, for example
if the trajectories were too stale and exceeded --max_policy_lag.
policy_stats¶
By default this section only contains the true_objective metrics: policy_stats/avg_true_objective,
policy_stats/avg_true_objective_max, policy_stats/avg_true_objective_min.
This will reflect the true_objective value if the environment returns one in the info dictionary
(see PBT for more details).
If true_objective is not specified these metrics should be equal to the scalar environment reward.
policy_stats will also contain any custom metrics (see Custom metrics) that are not in
<group_name>/<metric_name> format.
reward¶
reward/reward, reward/reward_max, reward/reward_min are the raw scalar environment rewards, reported
before any scaling (--reward_scale) or normalization is applied.
stats¶
stats/avg_request_count- how many requests from the rollout workers are processed per inference step. The correpondence between this number and the actual inference batch size depends on training configuration, this is mostly an internal metric for debugging purposes.stats/gpu_cache_learner,stats/gpu_cache_policy_worker,stats/gpu_mem_learner,stats/gpu_mem_policy_worker,stats/gpu_mem_policy_worker,stats/master_process_memory_mb,stats/memory_learner,stats/memory_policy_worker- a group of metrics to keep track of RAM and VRAM usage, mostly used to detect and debug memory leaks.stats/step_policy,stats/wait_policy- performance debugging metrics for the inference worker, respectively the time spent on the last inference step and the time spent waiting for new observations from the rollout workers, both in seconds.
train¶
This is perhaps the most useful section of metrics, many parameters can be used to debug RL training issues. Metrics are listed and explained below in the alphabetical order in which they appear in Tensorboard.

train/actual_lr- the actual learning rate used by the learner, which can be different from the configuration parameter if the adaptive learning rate is enabled.train/adam_max_second_moment- the maximum value of the second moment of the Adam optimizer. Sometimes spikes in this metric can be used to detect training instability.train/adv_max,train/adv_min,train/adv_std- the maximum, minimum, standard deviation of the advantage values. "Mean" value is not reported because it is always zero (we use advantage normalization by default).train/entropy- the entropy of the actions probability distribution.train/exploration_loss- exploration loss (if any). See--exploration_lossargument for more details.train/fraction_clipped- fraction of minibatch samples that were clipped by the PPO loss. This value growing too large is often a sign of training instability (i.e. learning rate is too high).train/grad_norm- the L2 norm of the gradient of the loss function after gradient clipping.train/kl_divergence- the average KL-divergence between the policy that collected the experience and the latest copy of the policy on the learner. This value growing or spiking is often concerning and can be a sign of training instability.train/kl_divergence_max- max KL value in the whole minibatch.train/kl_loss- value of the KL loss (if any). See--kl_loss_coeffargument for more details.
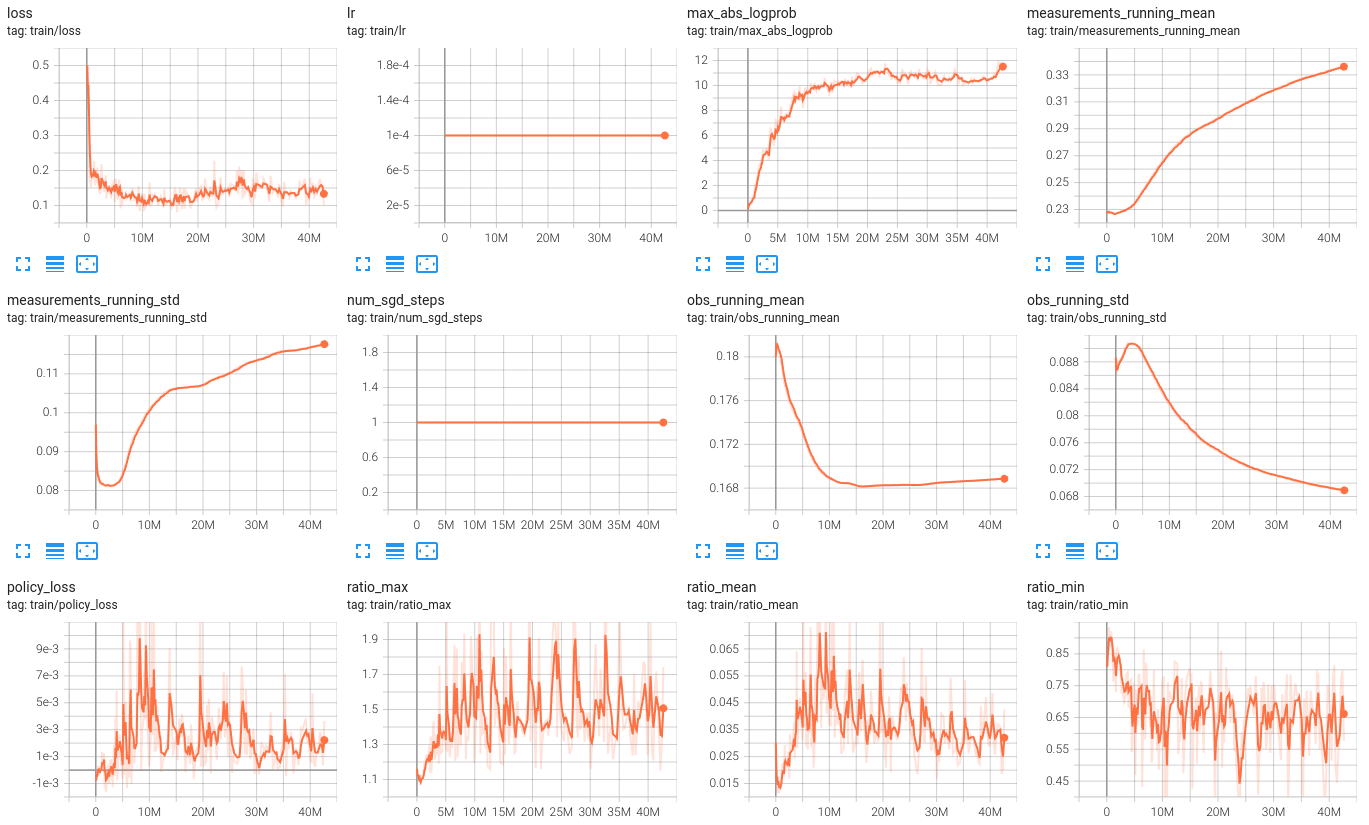
train/loss- the total loss function value.train/lr- the learning rate used by the learner (can be changed by PBT algorithm even if there is no lr scheduler).train/max_abs_logprob- the maximum absolute value of the log probability of any action in the minibatch under the latest policy. If this reaches hundreds or thousands (extremely improbable) it might be a sign that the distributions fluctuate too much, although it can also happen with very complex action distributions, i.e. Tuple action distributions.train/measurements_running_mean,train/measurements_running_std- in this particular example the environment provides the additional observation space called "measurements" and these values report the statistics of this observation space.train/num_sgd_steps- number of SGD steps performed on the current trajectories dataset when the summaries are recorded. This can range from 1 to--num_epochs*--num_batches_per_epoch.train/obs_running_mean,train/obs_running_std- the running mean and standard deviation of the observations, reported when--normalize_inputis enabled.train/policy_loss- policy gradient loss component of the total loss.train/ratio_max,train/ratio_mean,train/ratio_min- action probability ratio between the latest policy and the policy that collected the experience. Min/max/mean are across the minibatch.
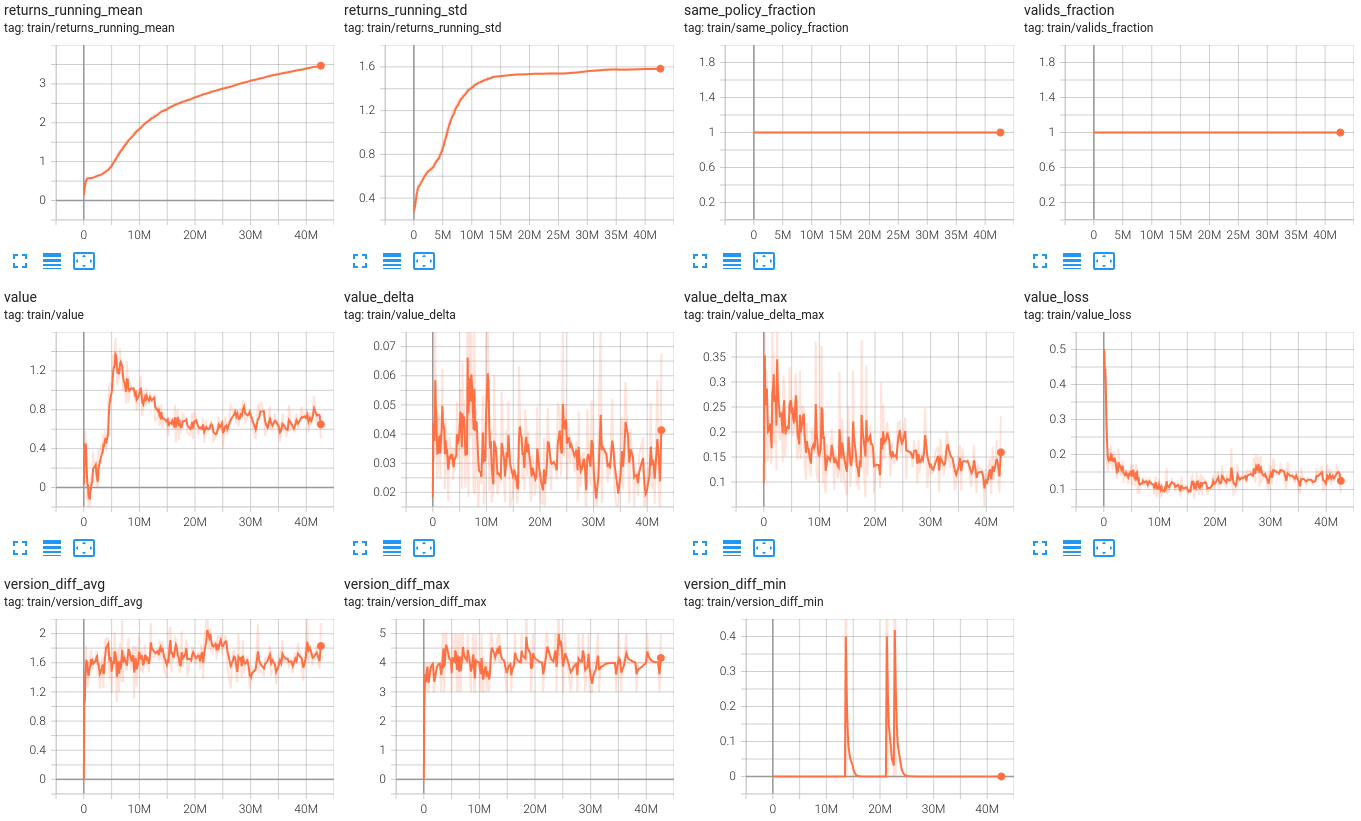
train/returns_running_mean,train/returns_running_std- the running mean and standard deviation of bootstrapped discounted returns, reported when--normalize_returnsis enabled.train/same_policy_fraction- fraction of samples in the minibatch that come from the same policy. This can be less than 1.0 in multi-policy (i.e. PBT) workflows when we change the policy controlling the agent mid-episode.train/valids_fraction- fraction of samples in the minibatch that are valid. Samples can be invalid if they come from a different policy or if they are too old exceeding--max_policy_lag. In most cases bothtrain/same_policy_fractionandtrain/valids_fractionshould be close to 1.0.train/value- discounted return as predicted by the value function.train/value_delta,train/value_delta_max- how much the value estimate changed between the current critic and the critic at the moment when the experience was collected. Similar totrain/ratio...metrics, but for the value function.train/value_loss- value function loss component of the total loss.train/version_diff_avg,train/version_diff_max,train/version_diff_min- policy lag measured in policy versions (SGD steps) between the policy that collected the experience and the latest policy on the learner.